
课程名称:基于Flink的湖仓一体化解决方案项目
培训周期:96课时
课程背景:
解决方案依托于市面上非常广泛的新零售业务作为背景,采用近年来出现的湖仓一体架构,解决了数据湖与数据仓库体系的割裂,在架构上把数据湖的灵活性、数据丰富性与数据仓库的企业级战略/战术分析支持能力进行融合,逐步演进成为集多源异构数据统一储存、多模型计算分析及统一数据治理的大数据综合解决方案;
基于数据湖的数据存储管理能力,以及同时支持上层计算引擎批和流的计算能力,帮助企业构建流批一体的数仓平台。
课程收获:
1.了解新零售行业背景;
2.了解顺丰优选大数据平台的项目背景;
3.掌握Lambda架构和Kappa架构优缺点;
4.掌握顺丰优选大数据项目技术架构;
5.掌握湖仓一体、流批一体的实现方式;
6.掌握数仓设计思路和方法;
7.熟悉顺丰优选的业务场景及需求;
8.掌握基于Flink SQL的实时数仓开发。
项目概述:
随着生鲜新零售行业的迅速发展,平台累计了大量数据。为了从已有的数据中挖掘出有价值的信息,黑马优选搭建了大数据处理平台。主要对各业务线的数据进行分析,从而便于精细化管理,最终提高用户数量及活跃度,提高商品销量,降低运营成本。
项目成果:
考虑到部分业务不需要实时,所以有单独的离线任务,但这些离线任务和实时任务共用同一套数据源(ODS层),并且共用同一套维度表。离线调度使用DolphinScheduler,实时调度使用Dlinky。
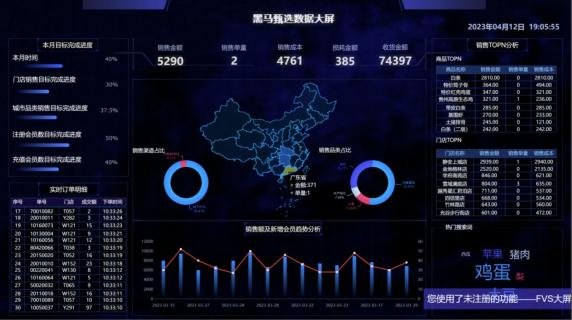
主要组件如下:
1.数据源:Mysql业务数据库
2.数据采集:使用Flink CDC + Flume
3.数据存储:使用Kafka/Hudi/Hive存储中间数据,使用Doris存储结果数据
4.数据计算:使用Flink DataStream/Flink SQL进行数据处理
5.数据分析:使用Doris灵活用于自定义数据分析
6.大数据平台应用:
(1)实时可视化:可以使用DataV,Sugar,FineBI等
(2)离线可视化:可以使用Metabase,Superset等
项目亮点:
1.以新零售为背景,更容易理解业务;
2.以真实项目做为模型打造,生动还原企业真实情况;
3.以时下最流行的流批一体、湖仓一体作为技术架构,技术先进;
4.数仓覆盖销售、会员、供应链、商城日志,主题多样,指标丰富;
5.从0到1进行数仓规划和搭建,极大提高实战能力;
6.充分发挥Flink CDC/Flink SQL/Flink DataStream进行编程,兼顾易用性和高效性;
7.以时下流行的Doris作为结果查询、报表展示和Ad-hoc组件,一件多用,简单高效;
8.实战应用Hudi,深入了解数据湖组件。
1. 需要具备大数据Flink基础;
2. 具备SQL语言基础。
1.了解新零售行业背景;
2.掌握Lambda架构和Kappa架构优缺点;
3.掌握流批一体、湖仓一体大数据项目技术架构;
4.掌握 Flink CDC 的应用场景及使用;
5.掌握 Flink 读写 Hive 操作;
6.掌握公共域、销售域的的需求及开发过程;
7.熟悉会员域、供应链域的需求及开发过程;
8.熟悉 Dinky、DolphinScheduler 的使用。
获取方式:请扫描下方二维码,回复【大数据】即可获取完整预习资料。

硬件:
硬件环境要求
1.PC机器CPU:8G Hz以上
2.PC机器内存:8GB以上
3、录音设备与扬声设备
软件:
软件环境要求:微信开发者工具最新版
7月25日
项目整体介绍
7月26日
FlinkCDC
7月27日
Flink集成Hive
7月28日
Hudi
7月30日
Doris
7月31日
业务开发(公共域)
8月1日
业务开发 (销售域)
8月2日
业务开发 (销售域)
8月4日
日志开发
8月5日
日志开发
8月6日
日志开发
8月7日
可视化
传智院校邦(www.ityxb.com)依托传智教育多年的IT教学经验和资源积淀,面向高校一直坚持 “协万千名校育人、助莘莘学子圆梦”的核心理念,提供丰富的校企合作模式。主要包括:课程置换、就业实训、师资培训、产学合作协同育人、专业建设等,每种模式现已形成稳固的高校合作生态系统,旨在深化教学改革,实现高校人才培养与企业发展的合作共赢。


